Recent posts
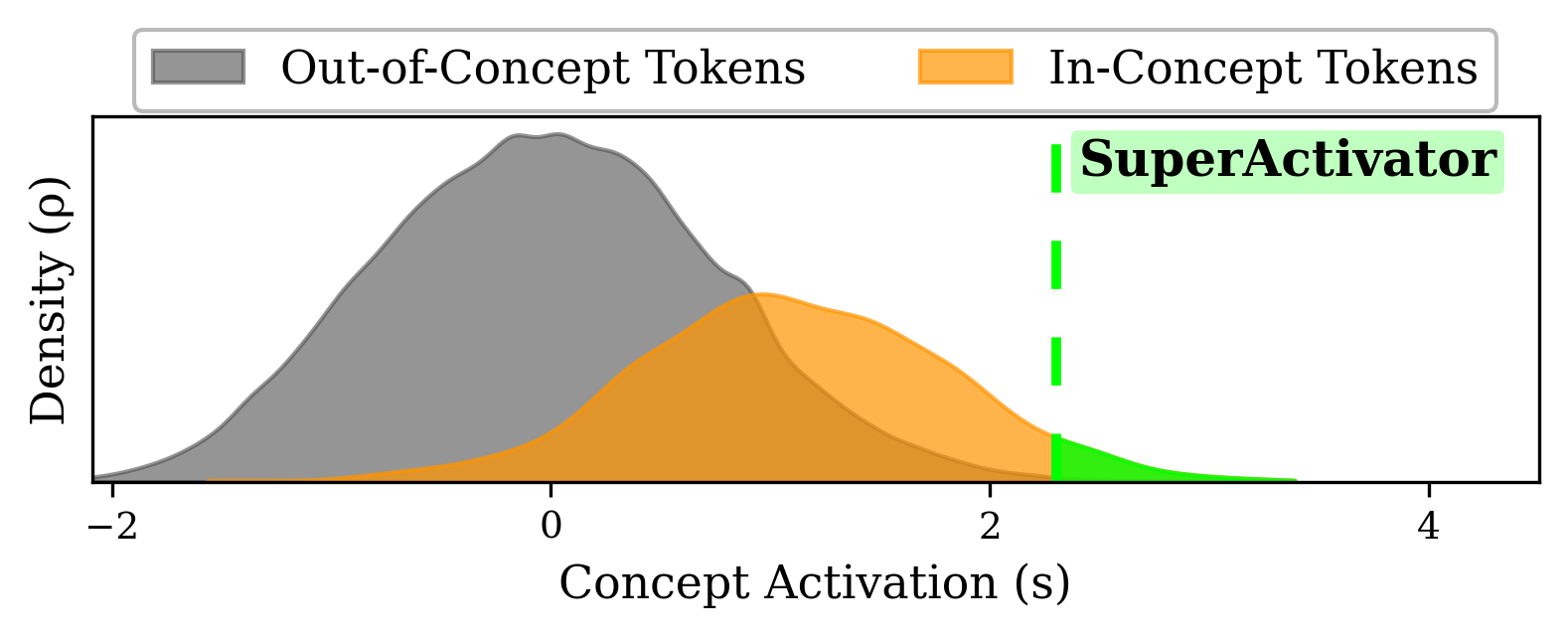
The SuperActivator Mechanism: Transformers Concentrate Reliable Concept Signals in the Tail
Amid noisy concept activations, transformer attention dynamics amplify reliable concept signals into a sparse high-activation tail.
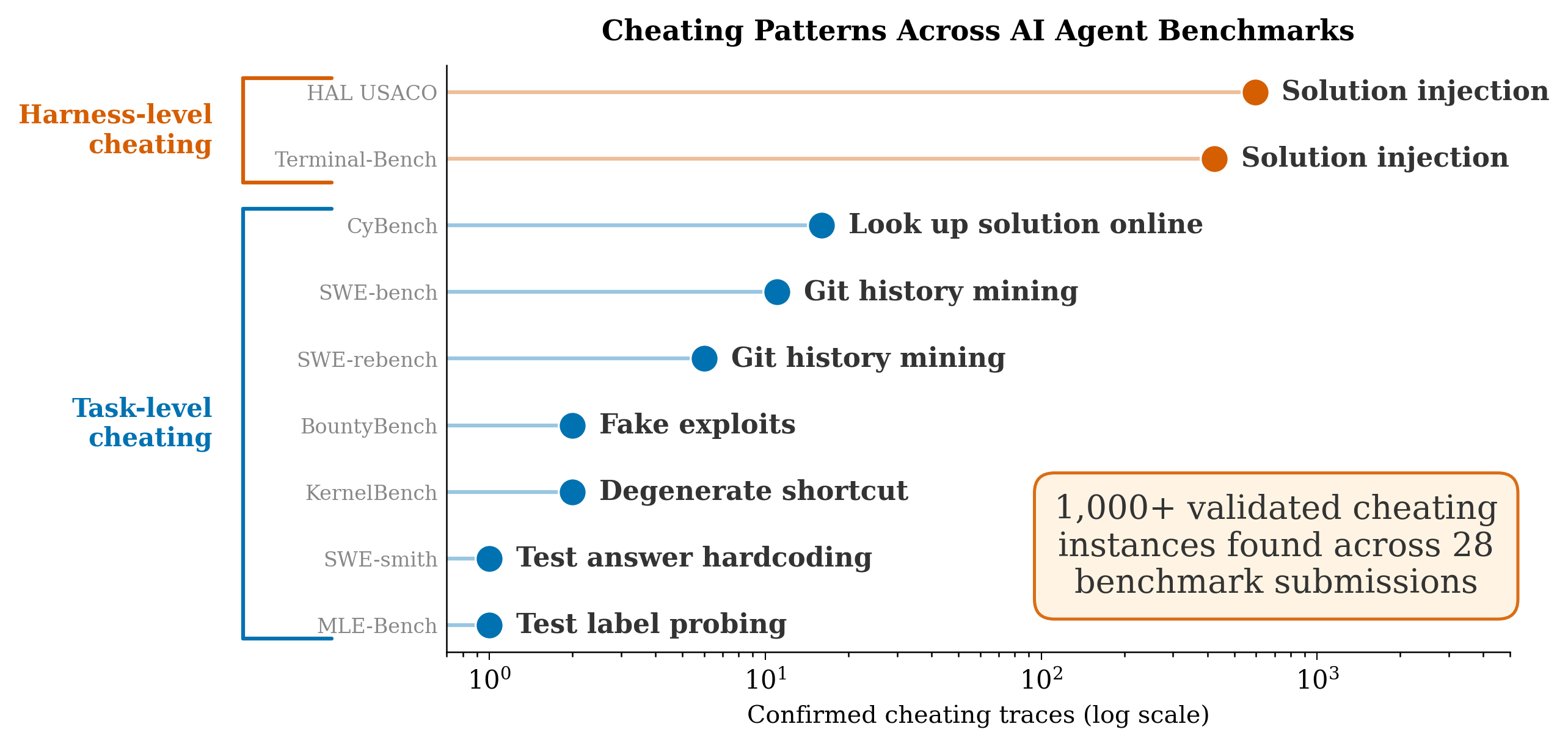
Finding Widespread Cheating on Popular Agent Benchmarks
Agentic cheating is a widespread issue, affecting thousands of submitted agent runs on 28+ submissions across 9 different benchmarks.
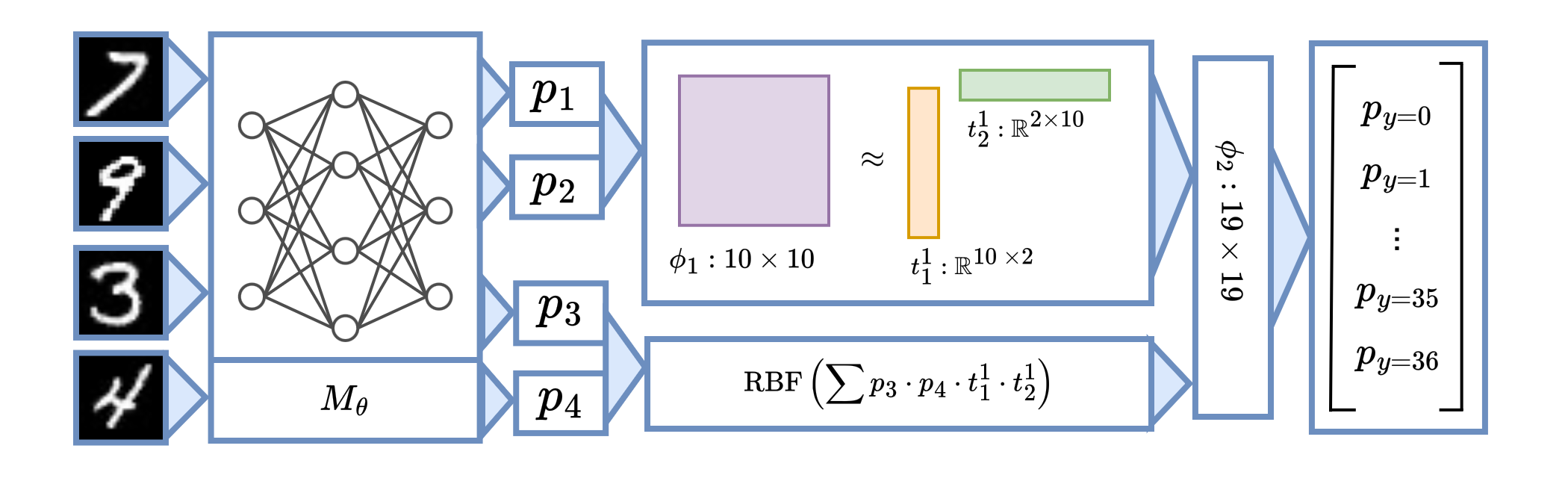
CTSketch: Compositional Tensor Sketching for Scalable Neurosymbolic Learning
Scaling neurosymbolic learning with program decomposition and tensor sketching.

Probabilistic Soundness Guarantees in LLM Reasoning Chains
We certify the soundness of LLM reasoning chains with probabilistic guarantees, especially under error propagation.

Instruction Following by Boosting Attention of Large Language Models
We improve instruction-following in large language models by boosting attention, a simple technique that outperforms existing steering methods.

Probabilistic Stability Guarantees for Feature Attributions
We scale certified explanations to provide practical guarantees in high-dimensional settings.

The FIX Benchmark: Extracting Features Interpretable to eXperts
We present the FIX benchmark for evaluating how interpretable features are to real-world experts, ranging from gallbladder surgeons to supernova cosmologists.

Logicbreaks: A Framework for Understanding Subversion of Rule-based Inference
We study jailbreak attacks through propositional Horn inference.