


Explanations for machine learning need interpretable features, but current methods fall short of discovering them. Intuitively, interpretable features should align with domain-specific expert knowledge. Can we measure the interpretability of such features and in turn automatically find them? In this blog post, we delve into our joint work with domain experts in creating the FIX benchmark, which directly evaluates the interpretability of features in real world settings, ranging from psychology to cosmology.
Machine learning models are increasingly used in domains like healthcare, law, governance, science, education, and finance. Although state-of-the-art models attain good performance, domain experts rarely trust them because the underlying algorithms are black-box. This lack of transparency is a liability in critical fields such as healthcare and law. In these domains, experts need explanations to ensure the safe and effective use of machine learning.
One popular approach towards transparent models is to explain model behaviors in terms of the input features, i.e. the pixels of an image or the tokens of a prompt. However, feature-based explanation methods often do not produce interpretable explanations. One major challenge is that feature-based explanations commonly assume that the given features are already interpretable to the user, but this is typically only true for low-dimensional data. With high-dimensional data like images and documents, features at the granularity of pixels and tokens may lack enough semantically meaningful information to be understood even by experts. Moreover, the features relevant for an explanation are often domain-dependent, as experts of different domains will care about different features. These factors limit the usability of popular, general-purpose feature-based explanation techniques on high-dimensional data.
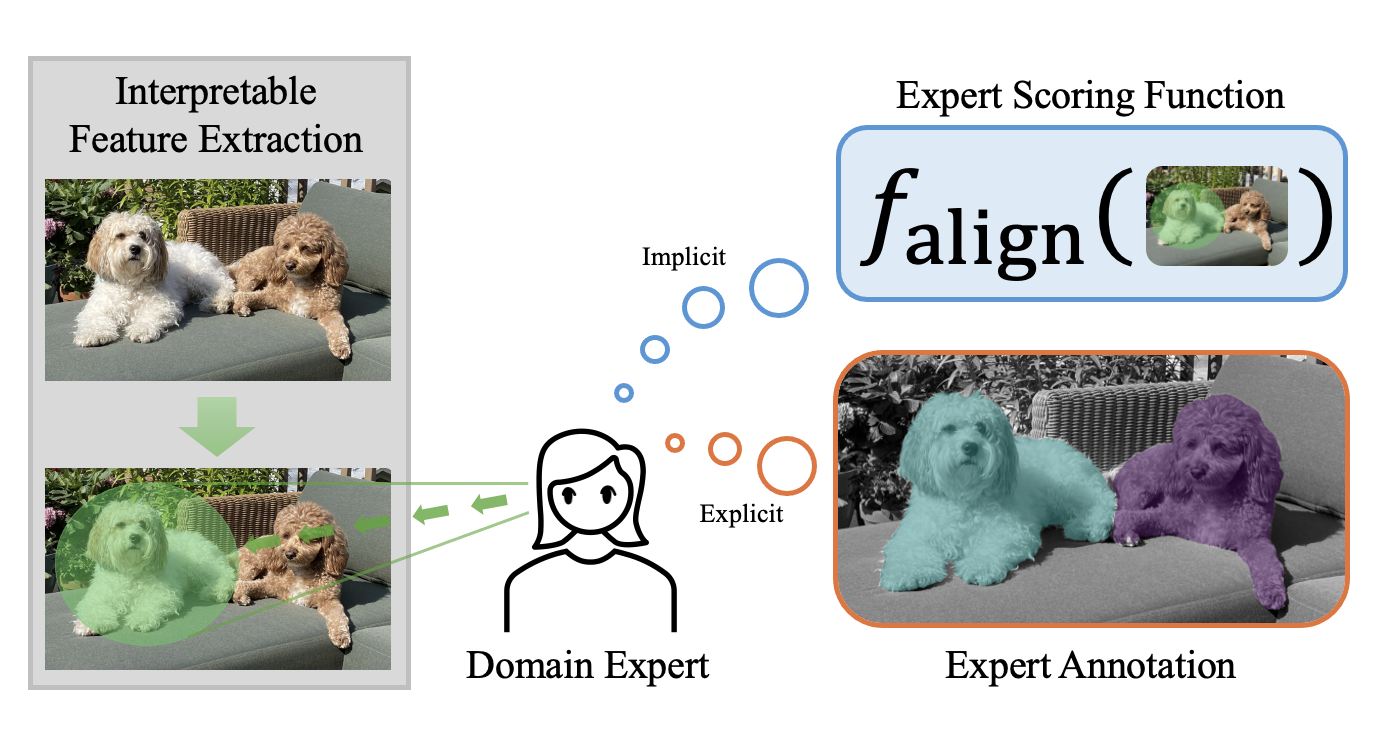
Instead of individual features, users often understand high-dimensional data in terms of semantic collections of low-level features, such as regions of an image or phrases in a document. In the figure above, a pixel as a feature would not be very informative, but rather the pixels that make up a dog in the image would make more sense to a user. Furthermore, for a feature to be useful, it should align with the intuition of domain experts in the field. Therefore, an interpretable feature for high-dimensional data should satisfy the following properties:
- Encompass a grouping of related low-level features, e.g., pixels, tokens, to create a meaningful high-level feature.
- These groupings should align with domain expert knowledge of the relevant task.
We refer to features that satisfy these criteria as expert features. In other words, an expert feature is a high-level feature that experts in the domain find semantically meaningful and useful. This benchmark thus aims to provide a platform for researching the following question:
Can we automatically discover expert features that align with domain knowledge?
The FIX Benchmark
Towards this goal, we present FIX, a benchmark for measuring the interpretability of features with respect to expert knowledge. To develop this benchmark, we worked closely with with domain experts, spanning gallbladder surgeons to supernova cosmologists, to define criteria for interpretability of features in each domain.
An overview of FIX is shown in the following table below. The benchmark consists of 6 different real-world settings spanning cosmology, psychology and medicine, and covers 3 different data modalities (image, text, and time series). Each setting’s dataset consists of classic inputs and outputs for prediction, as well as the criteria that experts consider to reflect their desired features (i.e. expert features). Despite the breadth of domains, FIX generalizes all of these different settings into a single framework with a unified metric that measures a feature’s alignment with expert knowledge. The goal of the benchmark is to advance the development of general purpose feature extractors that can extract expert feature across all diverse FIX settings.
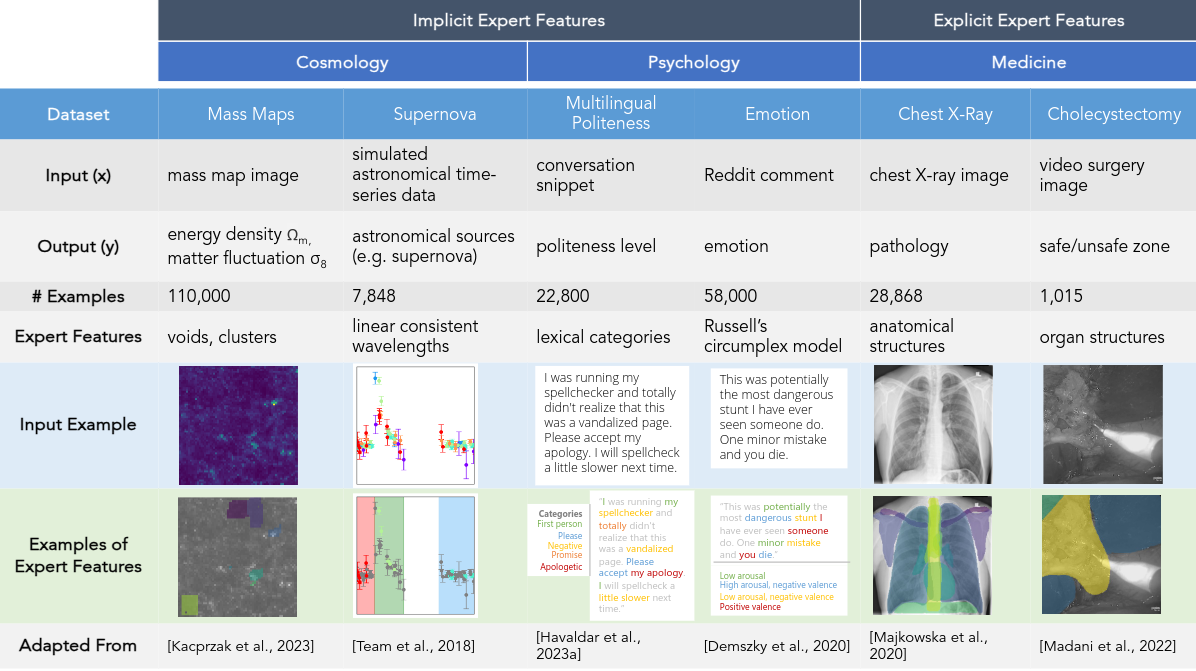
Expert Features Example: Cholecystectomy
As an example, in cholecystectomy (gallbladder removal surgery), surgeons consider vital organs and structures (such as the liver, gallbladder, hepatocystic triangle) when making decisions in the operating room, such as identifying regions (i.e. the so-called “critical view of safety”) that are safe to operate on.
[Warning!] Clicking on a blurred image below will show the unblurred color version of the image. This depicts the actual surgery which can be graphic in nature. Please click at your own discretion.
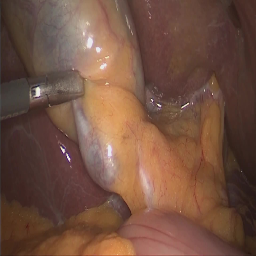


Therefore, image segments corresponding to organs are expert features. Specifically, we call this an explicit expert feature: such features can be explicitly labeled via mask annotations that show each organ (i.e. one mask per organ).
In FIX, the goal is to propose groups of features that align well with expert features. How do we measure this alignment? Let $\hat G$ also be a set of masks that correspond to proposed groups of features, called the candidate features.
To evaluate the alignment of a set of candidate features $\hat G$ for an example $x$, we define the following general-purpose FIXScore:
where \(\hat{G}[i] = \{\hat{g} : \text{group \(\hat{g}\) includes feature \(i\)}\}\) is the set of all groups containing the $i$th feature, and $\mathsf{ExpertAlign}(\hat g, x)$ measures how well a proposed feature $\hat g$ aligns with the experts’ judgment. In other words, the $\mathsf{FIXScore}$ computes an average alignment score for each individual low-level feature based on the groups that contain it, and summarizes the result as an average over all low-level features. This design prevents near-duplicate groups from inflating the score, while rewarding the proposal of new, different groups.
To adapt the FIX score to a specific domain, it suffices to define the $\mathsf{ExpertAlign}$ score for a single group. In the Cholecystectomy setting, we have existing ground truth annotations $G^\star$ from experts. These annotations allow us to define an explicit alignment score. Specifically, let $G^\star$ be a set of masks that correspond to explicit expert features, such as organs segments. We evaluate the proposed features with an intersection-over-union (IOU) between the proposed feature $\hat{g}$ and the ground truth annotations $G^\star$ as follows:
\[\mathsf{ExpertAlign} (\hat{g}, x) = \max_{g^{\star} \in G^{\star}} \frac{|\hat{g} \cap g^\star|}{|\hat{g} \cup g^\star|}.\]Implicit Expert Features
Explicit feature annotations are expensive: they are only available in two of our six settings (X-Ray and surgery), and are not available in the remaining psychology and cosmology settings. In those cases, we have worked with domain experts to define implicit alignment scores that measures how aligned a group of features is with expert knowledge without a ground truth target. For example, in the multilingual politeness setting, the scoring function measures how closely the text features align with the lexical categories for politeness. In the cosmological mass maps setting, the scoring function measures how close a group is to being a cosmological structure such as a cluster or a void. See our paper for more discussion on these implicit alignment scores and what they measure.
To explore more settings, check out FIX here: https://brachiolab.github.io/fix/
Citation
Thank you for stopping by!
Please cite our work if you find it helpful.
@article{jin2024fix,
title={The FIX Benchmark: Extracting Features Interpretable to eXperts},
author={Jin, Helen and Havaldar, Shreya and Kim, Chaehyeon and Xue, Anton and You, Weiqiu and Qu, Helen and Gatti, Marco and Hashimoto, Daniel and Jain, Bhuvnesh and Madani, Amin and Sako, Masao and Ungar, Lyle and Wong, Eric},
journal={arXiv preprint arXiv:2409.13684},
year={2024}
}