Concept vectors are meant to be helpful interpretability tools, associating directions in a model’s latent space with human-understandable concepts. However, in practice their activations are noisy and inconsistent. Within this noise, we find a clear pattern: as activations pass through transformer layers, concept-aligned heads amplify the most extreme signals into a sparse high-activation tail. These high-tail tokens, which we call SuperActivators, provide a clear signal of concept presence.
Where Is the Concept, Actually?
Concept vectors give us a lightweight way to connect human-meaningful ideas (like objects, attributes, or emotions) to a model's internal representations, helping us understand and sometimes influence opaque deep learning models.
For a given image or text sample, we score each token by how strongly it aligns with that concept; ideally, true concept tokens score higher than the rest. In practice, these activation scores are noisy and unreliable, misrepresenting true concept presence.
In the COCO example, the activation heatmaps for Animal and Person appear to highlight the same tokens, even though only Animal is present. As a result, if you only saw the Person heatmap, you might incorrectly assume a person is in the image. The reverse also happens: even when Car is present, many true Car tokens barely activate for the Car concept.
Such noisy activation signals make it difficult to reliably detect or localize concepts. This raises the question:
To answer this question, we zoom out beyond a single image or text sample and look at activation distributions across a dataset.
The SuperActivator Mechanism Cuts Through the Noise
While most activations remain noisy, we discover that a small set of reliable concept signals concentrates in the upper tail of the in-concept activation distribution. This tail forms through a transformer dynamic, which we call the SuperActivator Mechanism, where already concept-aligned tokens are amplified across layers until they separate from the surrounding noise.
The resulting high-tail tokens, or SuperActivators, are reliable concept signals because they exhibit two key properties:
- Precision: when the signal fires, it is distinguishable from out-of-concept noise.
- Recall: the signal appears in most samples where the concept is present.
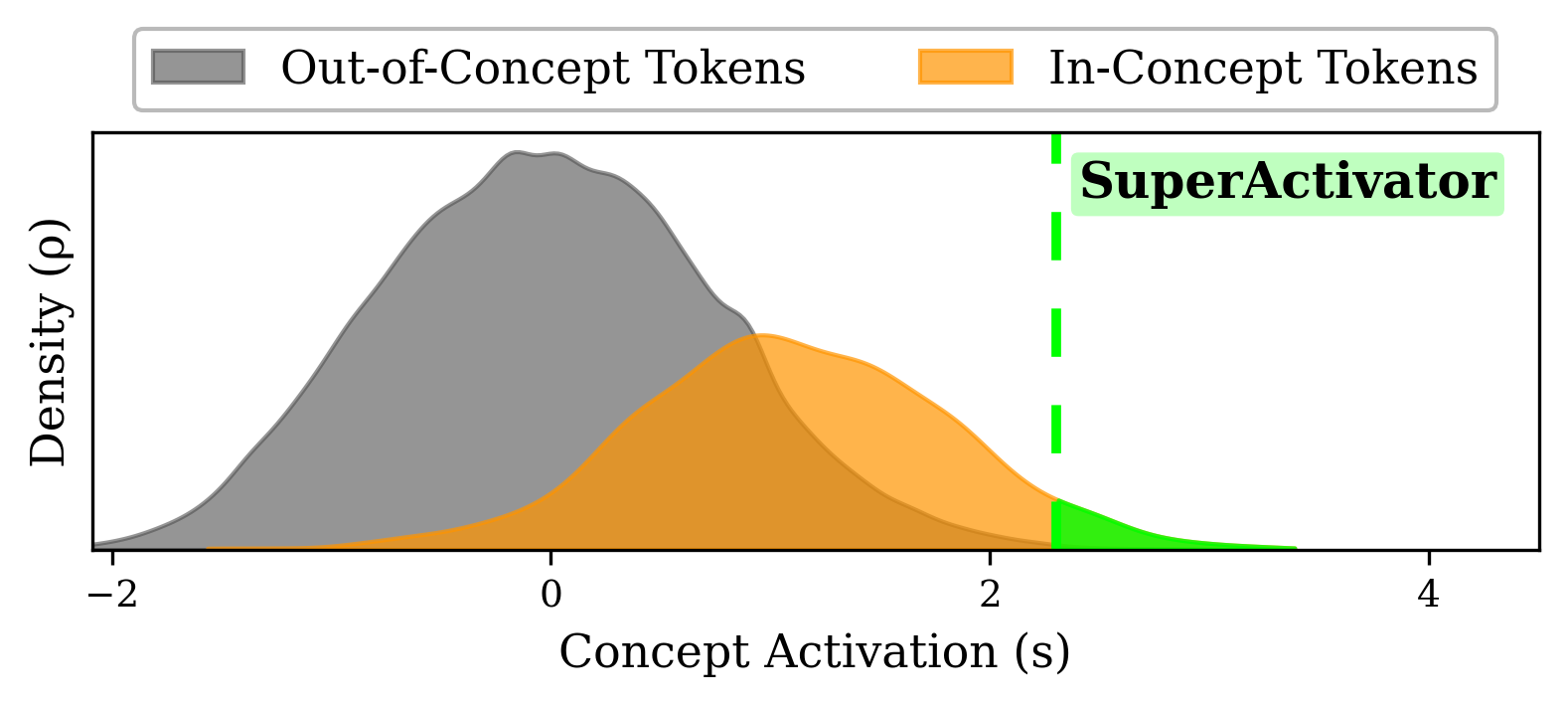
Operationally, SuperActivators are defined by a sparsity parameter, δ, which isolates the top percentile of the in-concept distribution, so δ = 0.05 keeps the top 5% of in-concept activations.
We observe the same pattern across many settings:
| Modalities | Concept Types | Models |
|---|---|---|
|
Image 4 datasets Text 3 datasets |
Mean prototypes Linear separators K-Means clusters K-Means separators |
CLIP LLaMA-3.2-Vision-Instruct Gemma-2-9B Qwen3-Embedding-4B |
This breadth suggests that the SuperActivator Mechanism reflects a general principle of how transformers encode semantics.
Where Do SuperActivators Come From?
To understand where SuperActivators come from, we first examine how activation distributions evolve through the model, then provide a theoretical analysis of why concept-aligned attention creates this tail.
Separation Emerges in the Tail Across Layers
Below, we track activation distributions across model layers for tokens labeled as in-concept versus out-of-concept.
In early layers, the out-of-concept distribution is roughly normal and centered around 0, while the in-concept distribution looks similar but with a slight positive shift or skew.
As we move deeper, the concept signal does not get stronger everywhere: most in-concept activations still overlap with the out-of-concept distribution, which explains the observed noise. However, a small high-activation tail pulls away cleanly enough to give us precision.
Crucially, we also observe that most in-concept samples have at least one activation in this well-separated tail, giving us recall.
Theory: Why This Tail Emerges
For a transformer model to propagate a concept signal forward, we assume at least one attention head in each layer has a concept-aligned read-write path.
Here, we present the idealized case where these attention heads are perfectly concept-aligned, with no interference from other heads, MLPs, or output projection mixing. Nearly the same results hold with noise, as long as the concept signal is large enough.
Under these assumptions, the residual update has a simple structure: each token keeps its current concept activation and receives an attention-weighted update from the other tokens.
We first prove that this residual attention update amplifies concept activation differences in general:
If any two tokens already differ in concept activation, a concept-aligned attention head makes that gap larger in the next layer.
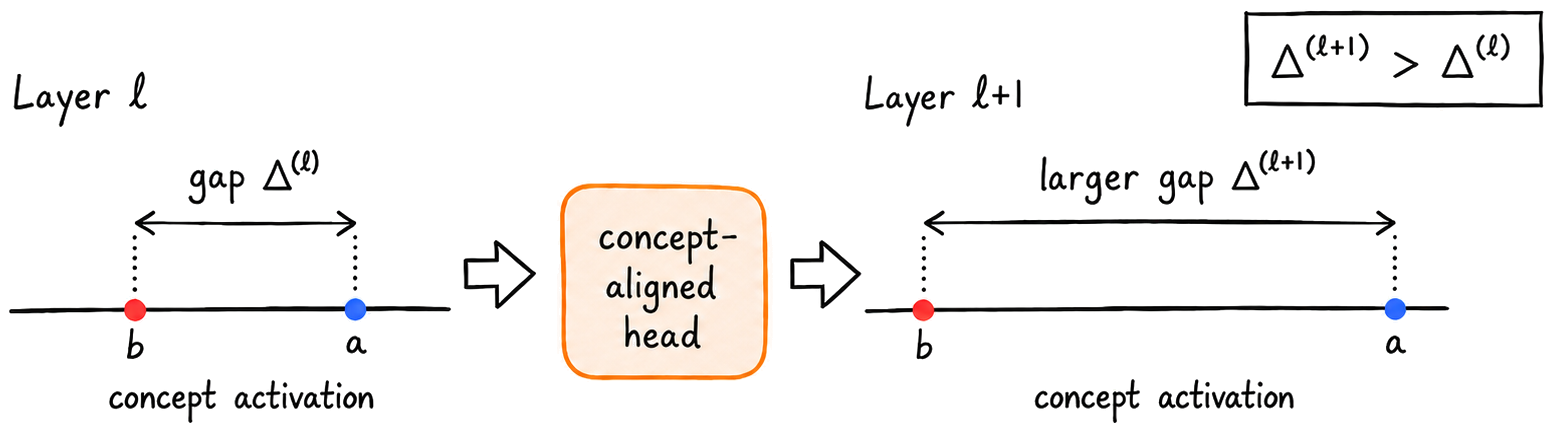
This has two direct consequences:
As activation gaps grow, attention increasingly concentrates on the most extreme tokens.
Once attention has concentrated on the extremes, same-tail tokens attend to the same extreme token and receive nearly the same update, which drives the second consequence:
Relative activations within the same tail eventually equalize.
SuperActivators arise in the finite-depth regime of real transformers, after the tail has separated but before it collapses into this uniform behavior.
We next prove where activation gap growth is strongest:
Any existing skew in the activation distribution is amplified across layers.
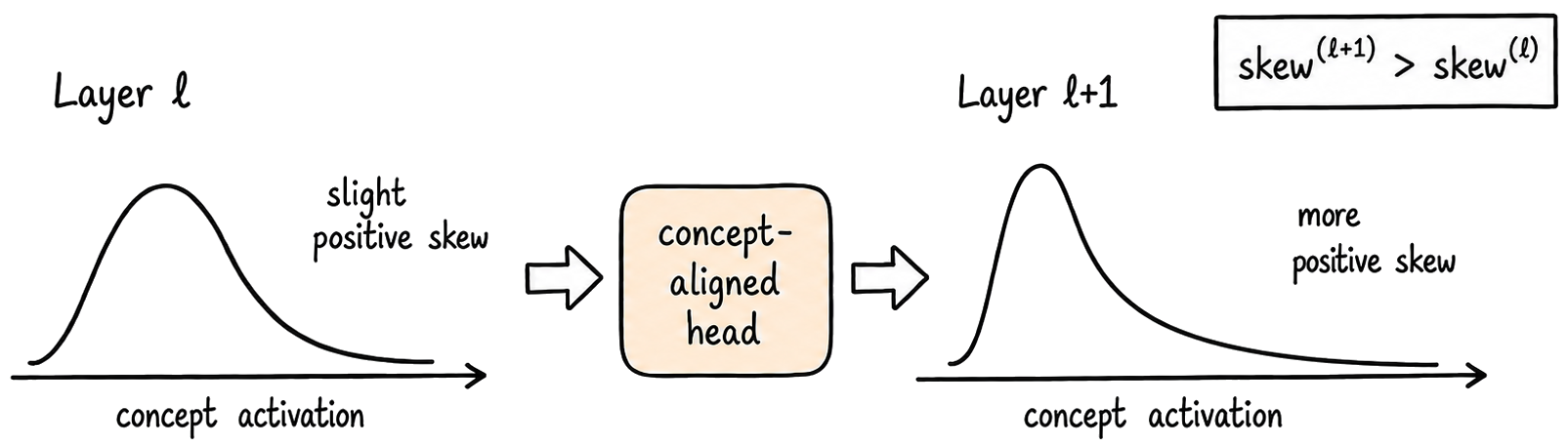
The slight positive tail we observe early on is amplified by concept-aligned heads into the increasingly extreme high-activation tails we see empirically.
SuperActivators Provide Reliable and Localized Concept Signals
We evaluate the extreme tail implied by the theory on two tasks:
- concept detection: whether a concept is present anywhere in a sample, and how sparse the reliable evidence can be
- concept localization: where a concept appears within a sample
SuperActivators Improve Detection with Sparse Evidence
We predict that a concept is present if the sample contains a SuperActivator:
Methods
Notably, our SuperActivator-based method consistently outperforms all other concept detection baselines, improving F₁ scores by up to 0.14.
By sweeping the sparsity threshold, we find that performance consistently peaks when using only a small fraction of the most highly activated tokens—typically between δ=5-10%. Adding more tokens from the labeled concept region intuitively seems like it should help, but actually hurts performance.
SuperActivators Improve Attributions
Instead of explaining the global concept vector, we explain alignment with the local SuperActivators.
As shown in the examples above, global concept vector attributions are very noisy, while SuperActivator attributions concentrate much more cleanly on the actual concept.
Besides improving accuracy, SuperActivator-based attributions are also more faithful: the tokens they highlight increase the model’s concept alignment when inserted and reduce it when removed.
Crucially, these improvements aren’t tied to any single explainer. We tested nine different attribution methods, and every single method improved when we swapped the global vector for the SuperActivator objective.
Key Takeaway
Ignore the bulk, only trust the tail.
For more details, see our paper and code.
Citation
@article{goldberg2025superactivators,
title={The SuperActivator Mechanism: Transformers Concentrate Reliable Concept Signals in the Tail},
author={Goldberg, Cassandra and Kim, Chaehyeon and Stein, Adam and Wong, Eric},
journal={arXiv preprint arXiv:2512.05038},
year={2025},
url={https://arxiv.org/abs/2512.05038}
}